





Description
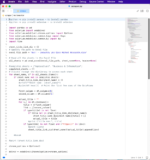
Built in Python using Selenium, our web scraper targets any webpage you like (dependant on website security), in order to pull readable content into a digestible format.
Targeted URLs must be stored in an Excel spreadsheet, in order for the tool to pick them up and iterate through for data extraction. The tool operates automatically without the need for user intervention, meaning you can leave the tool to do its work whilst you carry out other tasks.
We use this solution for data mining initiatives to extract HTML data in bulk, ensuring we abide by data laws and regulations throughout the process. Data values can be filtered by categories or key attributes for additional classification.


Reviews
There are no reviews yet.